

06 Abr Google anunció el lanzamiento de BigLake: ¿De qué va este nuevo proyecto?
Google presenta BigLake como una solución para eliminar las restricciones existentes entre los lagos de datos y los almacenes.

Google Cloud acaba de anunciar la vista previa de BigLake, un motor de almacenamiento unificado que simplifica el acceso a los datos almacenados en Lake y Warehouse.
El objetivo principal de Google es eliminar por completo los limites de datos, así como romper las barreras existentes entre los lagos de datos y los almacenes.
«BigLake permite a las empresas unificar sus almacenes de datos y lagos para analizar datos sin preocuparse por el formato o sistema de almacenamiento subyacente, lo que elimina la necesidad de duplicar o mover datos de una fuente y reduce los costos y las ineficiencias»
Gerrit Kazmaier, Vicepresidente y Director General de Bases de Datos de Google Cloud
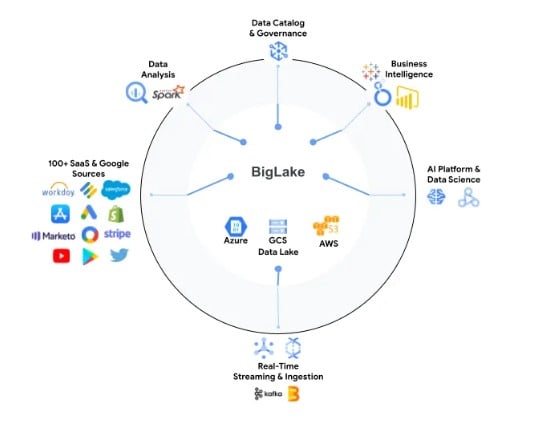
Lo que significa que BigLake esta diseñado para ofrecer una interfaz unificada en cualquier capa de almacenamiento, sin tener la necesidad de mover ningún dato. Todo en un mismo sitio.
De esta forma, BigLake se encontrará en el centro de la estrategia de Google Cloud con respecto a la plataforma de datos y el proveedor de la nube solo se enfocará en integrar todas las herramientas con ella, según Sudhir Hasbe.
«Vamos a integrar a la perfección nuestra capacidad de gestión y gobernanza de datos con Dataplex, por lo que cualquier dato que entre en BigLake se gestionará y se regirá de manera consistente (…) Todas nuestras capacidades de aprendizaje automático e IA… también funcionarán en BigLake, así como en todos nuestros motores de análisis, ya sea BigQuery, si es Spark, si es Dataflow»
Sudhir Hasbe, Director de Gestión de Productos para Análisis de Datos de Google Cloud
Cabe destacar que BigLake admitirá todo los formatos y estándares de archivo de código abierto como Parquet y ORC, junto a nuevos formatos para el acceso a mesas como Delta o Iceberg, así como motores de procesamiento de código abierto como Apache Spark o Beam.
[unocero.com]